RAG pipelines let language models answer using your documentation, support tickets, policies, and internal knowledge, with citations back to the original source.
In production, that means more than connecting a model to a vector database. It means building a system that ingests and updates source content reliably, retrieves the right evidence quickly, structures prompts safely, and gives teams a clear way to measure answer quality over time.
This guide covers the full production pipeline: ingestion, extraction and transformation, chunking, embeddings, vector and hybrid search, prompt construction, evaluation, and security. It also explains how these stages connect into a system you can monitor, debug, and improve as usage grows.
You’ll learn how to:
- build a modular RAG architecture that fits your existing stack
- choose chunking and indexing strategies for reliable retrieval
- structure prompts and guardrails that keep answers grounded in source context
- evaluate retrieval quality, citation accuracy, latency, and cost
- troubleshoot common production issues around data quality, fragmentation, and access control
This guide is for ML engineers, platform teams, and technical product leaders moving from RAG demos to production systems serving real users.
Key Takeaways on Building Production-Ready RAG Pipelines
- Ingestion and extraction come first. The system pulls clean, structured text from documents, apps, databases, and knowledge sources before anything reaches the model. Bad input produces bad output.
- Chunking and indexing determine retrieval quality. How you split, label, and embed content shapes how well the system finds relevant context later.
- Retrieval strategy matters. Vector search, keyword search, and hybrid search each suit different use cases. Choose based on your data type and query patterns.
- Evaluation belongs in the pipeline, not after deployment. Measure answer quality, retrieval relevance, citation accuracy, latency, and cost before you scale.
- Security and architecture decisions compound as complexity grows. Advanced variants like Agentic RAG or GraphRAG solve problems that standard retrieval cannot: multi-step reasoning, connected knowledge, and complex workflows.
Core Components of a RAG Pipeline
A RAG system works like a chain. Each stage shapes the next stage. So it’s important to be aware that a weak corpus (structured material used in training) will create weak retrieval. Weak retrieval will create a weak augmented prompt. And a weak prompt will create fluent but wrong answers.
Production teams treat the RAG pipeline as a data system first. That mindset pushes you toward clean interfaces, stable metadata, and measurable quality.
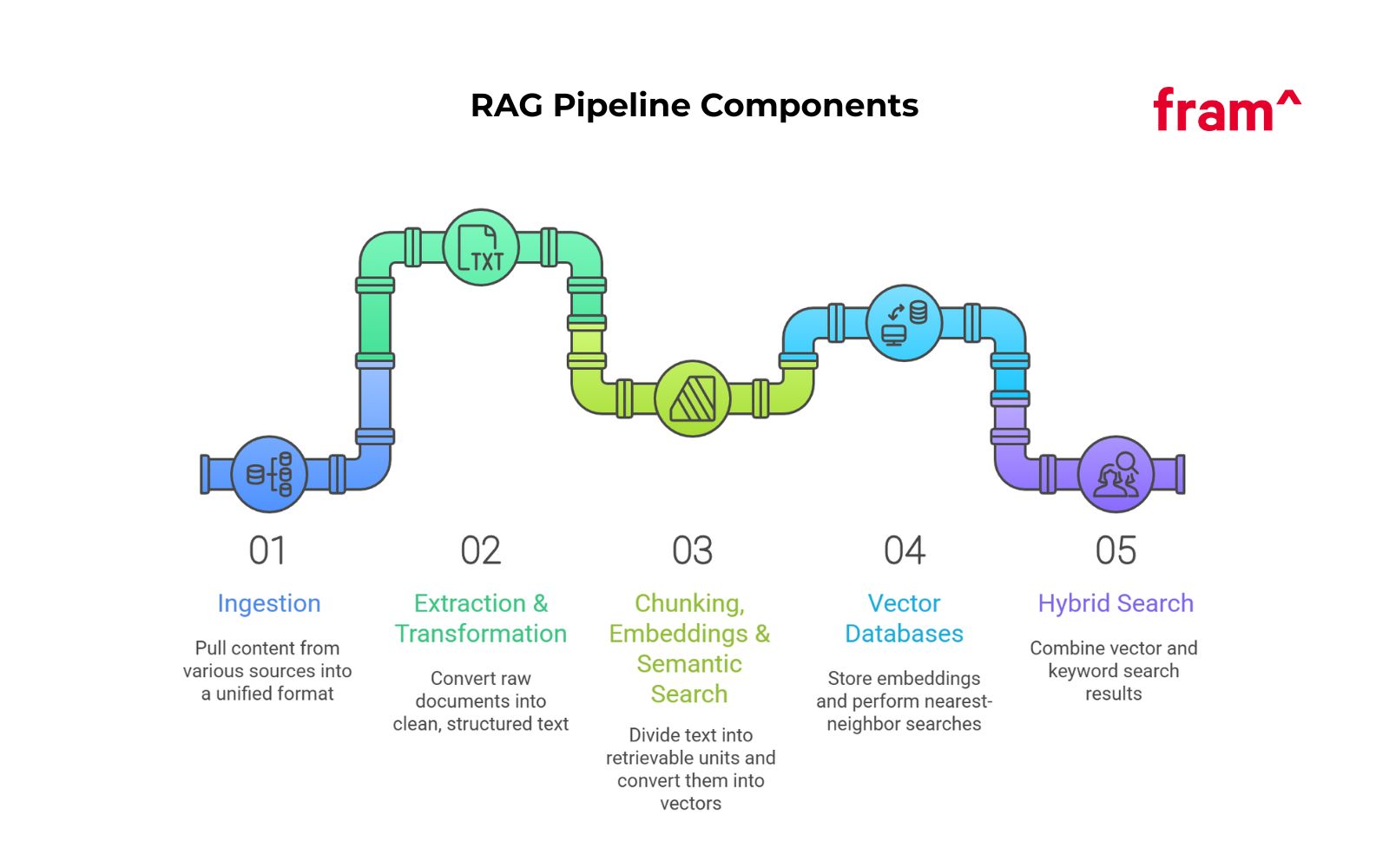
Ingestion
Ingestion pulls raw content from many knowledge sources and normalizes it. Sources are often pulled from your internal knowledge base, including PDFs, HTML pages, wikis, tickets, and shared docs. LangChain’s document loaders exist for this exact reason. They read data from many sources and convert them into a consistent Document format.
Two properties drive ingestion success: coverage and freshness.
Coverage answers one thing: Can the system see what users rely on? If your help center lives in one tool and your runbooks live in another, ingestion must pull both.
Freshness answers another thing: Does the index reflect the latest version fast enough? A stale policy answer breaks trust in one shot.
A practical ingestion setup uses two lanes.
One lane runs batch backfills. It handles re-indexes and big migrations. The second lane runs incremental updates. It handles daily or hourly changes.
Extraction and transformation
Ingestion collects files. Extraction turns files into usable text. Transformation cleans and structures that text.
Real documents arrive messy. PDFs repeat headers and footers. HTML mixes nav menus with content. Ticket exports include signatures and quoted threads.
Extraction should preserve the structure that matters for meaning. Titles, section headings, and table boundaries matter. Source attribution also matters. A RAG answer that cites the wrong page still fails.
Keep transformation focused on retrieval quality:
- Strip boilerplate.
- Normalize whitespace.
- Remove repeated page furniture.
- Keep code blocks and table rows stable.
This stage also sets metadata. Store fields like source URL, document owner, last updated date, access tags, and content type. Those fields power filters later. They also help the system explain where an answer came from.
Chunking, embeddings, and semantic search
Chunking splits long text into smaller units that retrieval can return. These chunks power semantic search, allowing retrieval by meaning rather than keywords. The model cannot read an entire handbook on every question. It reads a small set of chunks inside the prompt.
LangChain’s text splitters describe this goal directly. They break large docs into smaller chunks that fit context limits and stay retrievable as units.
Chunk size changes retrieval behavior.
Large chunks keep context, and they help with definitions and prerequisites. They also dilute the matching signal. A large chunk can contain a relevant sentence plus three unrelated sections.
Small chunks match tightly, and they cut noise. They also lose context near boundaries. The answer may miss the definition that sits one paragraph earlier.
Overlap reduces boundary loss. But it also increases index size, which leads to increased embedding cost and increased storage. So overlap is a trade-off.
Semantic segmentation helps when topic shifts matter. LlamaIndex documents a “semantic chunker” that selects sentence boundaries based on embedding similarity, rather than fixed sizes.
Embeddings convert text into vectors. Vectors let the system search by meaning, not exact words. OpenAI describes embeddings as a numerical representation of text used to measure relatedness between pieces of text.
You also need a distance or similarity function.
Cosine similarity measures the angle between vectors. Euclidean distance measures straight-line distance. Dot product measures alignment and magnitude. Cohere lists these metrics for its embed models and notes support for cosine, dot product, and Euclidean distance.
Where does tokenization show up? It shows up in cost and limits. Tokenizers decide how many tokens you send for embedding and generation. OpenAI’s embeddings API reference notes input constraints and max input tokens for embedding models.
Vector databases
Vector databases store embeddings and serve nearest neighbor search. They also store metadata fields so you can filter by tenant, product, region, or access level.
Many production systems rely on approximate nearest neighbor search. HNSW is a widely used graph-based ANN method described in Malkov and Yashunin’s paper.
Scale shifts the hardware question. At a moderate scale, CPU search often works. But at a very large scale, GPU acceleration can cut latency and raise throughput.
FAISS introduced GPU work that targets billion-scale similarity search and shows large speedups for k-NN style operations.
RAPIDS cuVS documents itself as a GPU library for approximate and exact nearest neighbors and clustering, built to simplify GPU vector similarity search.
Vector infrastructure also supports future changes. When you swap embedding models, you can re-embed and re-index the vector database. When you add new repos, you can ingest and embed without retraining the LLM.
Hybrid search
Vector search matches meaning. Keyword search matches tokens. Production retrieval augmented generation often needs both.
Hybrid search runs vector search and BM25-style keyword search, then fuses results into one ranked list. Weaviate documents hybrid search as a fusion of vector results and keyword results that use BM25F, with configurable weights and a fusion method.
Hybrid retrieval helps when exact strings matter. Product names, CVE IDs, error codes, and legal terms often need lexical matching. Dense retrieval can miss these exact anchors.
Fusion methods matter. Reciprocal Rank Fusion (RRF) is a simple method for combining result sets from multiple IR systems. The original SIGIR paper describes RRF and reports consistent gains over individual systems.
Elastic documents RRF as a method that combines multiple result sets into a single result set, and notes that it needs no tuning.
Hybrid search also improves reliability. You reduce the chance that a query fails due to a single data retrieval mode.
How a RAG Pipeline Works in Practice

A production RAG pipeline has two flows:
- One flow runs offline and prepares the index.
- The other flow runs at runtime and answers user queries.
Keep the stages modular. Modularity makes debugging and scaling easier. LangChain describes retrieval workflows as modular building blocks. Teams can swap loaders, splitters, embeddings, and vector stores without rewriting the whole app. This flexibility matters for evolving RAG applications.
Modular, sequential processing
The offline flow often looks like this:
Sources enter through loaders. Parsers extract text and metadata. Transformers clean and normalize. Splitters chunk. Embedding models vectorize. Index builders write into the vector store.
The runtime flow often looks like this:
A user query is entered. A retriever selects candidate chunks. A prompt builder assembles an augmented prompt. The LLM generates. A post step attaches citations and formats the output.
This separation also supports incident response. A spike in bad answers may trace back to parsing, indexing, or reranking. Logs can pinpoint which stage regressed.
Data indexing
Indexing stores vectors plus metadata and chunk text. Indexing also handles updates.
Updates come in three forms.
Upserts add new chunks and replace changed chunks. Deletes remove chunks from the removed documents. Rebuilds handle large shifts such as an embedding model change or a chunking strategy change.
Automating updates is central. Users ask about the latest runbook step. They ask about the latest policy clause. If your index refresh lags by weeks, the system stays wrong in the places that matter.
Retrieval and prompt construction work together
Retrieval selects chunks. Prompt construction decides how the model reads them.
Retrievers sit at the center of this contract. LangChain defines a retriever as an interface that returns documents given an unstructured query, and it notes that it is more general than a vector database.
A production retriever often uses a two-stage pattern.
Stage one retrieves a broader set using fast search. This can be dense, sparse, or hybrid. Stage two reranks a smaller set using a stronger scoring method. This step can use a cross-encoder reranker or a learned ranker.
Chunk size and top-k interact. A small chunk size often needs a larger top-k to keep context intact. A large chunk size often needs a smaller top-k to stay within prompt limits.
Prompt construction then does three jobs.
It sets rules for the model. It injects the retrieved context. It sets the output format and citation format.
A clean template separates instructions from retrieved text. It labels each chunk with source metadata. It also uses clear delimiters so the model treats retrieved text as evidence, not as instructions.
Prompt engineering
Prompt engineering in RAG is less about clever phrasing. It is more about a stable structure.
A production prompt template often includes:
A short task statement. A rule that the model must use the retrieved context only. A citation requirement. A fallback rule for missing evidence. A formatting spec for steps, tables, or JSON.
What happens when retrieval fails? The template should force a safe response. It should say the system lacks evidence in the retrieved sources. Then it should ask for a narrower query or point to missing coverage in the index.
This rule reduces hallucinations. It also surfaces gaps in ingestion and indexing.
Tokenization matters here, too. Token limits cap how much context you can pass. The embeddings API also enforces input limits for embedding requests. So token accounting belongs in both offline and runtime paths.
Evaluation and feedback loop
RAG systems improve through measured iteration. Logs and evals reveal where failures happen. Then teams fix the stage that caused the problem instead of guessing.
A practical evaluation loop tracks retrieval quality, answer quality, and operational cost.
Key metrics
- Retrieval quality measures whether the retriever surfaces the right documents or passages for a given query. Failures here usually trace back to weak chunking, poor metadata, low-quality embeddings, or an untuned search strategy.
- Groundedness measures whether the model’s answer is actually supported by the retrieved context. Failures here usually point to weak prompt rules, poor source selection, or the model filling gaps with unsupported claims.
- Citation accuracy measures whether citations point to the correct supporting evidence. Failures here usually mean the wrong chunks were retrieved, the prompt does not enforce citation behavior clearly enough, or post-processing attaches references incorrectly.
- Latency measures how long the system takes to return a response. Failures here usually come from slow retrieval, expensive reranking, large prompts, or multi-step orchestration adding too much overhead.
- Cost measures the runtime expense of retrieval, reranking, and generation. Failures here usually mean the pipeline retrieves too much context, uses expensive models too early, or is overengineered for a use case that does not require it.
Three layers of evaluation
A practical loop has three layers:
- Fixed test sets: Representative user questions with expected sources. Run these on every pipeline change.
- Periodic human review: Sample real traffic and score retrieval relevance, answer quality, and citation accuracy manually.
- Automated scoring: Run this before each release to catch regressions early.
Where fixes usually land
When evaluation fails, the fix often lands upstream. Low retrieval quality often traces to chunk noise or weak indexing. Low groundedness often traces to poor evidence selection. Citation problems often trace to prompt structure or output formatting. High latency and cost usually point to pipeline design choices, not model quality.
Query Transformation and Reranking
Query transformation and reranking improve retrieval quality before you reach for more complex architectural changes. Both target the same problem: the gap between what users ask and what the retriever finds.
Query transformation improves the search input
Query transformation rewrites or restructures user input so the retriever finds the right information. This matters most in conversational systems, where users ask vague follow-ups or rely on shared context.
A query like “How about Emily Doe?” becomes “When was the last time Emily Doe bought something from us?” before retrieval. Broad questions get decomposed into subqueries so the system retrieves evidence from multiple sources.
Use query transformation when queries are ambiguous, context-dependent, or too broad for a single retrieval step.
Metadata filters improve precision
Smarter models do not solve every retrieval problem. Sometimes the biggest gain comes from narrowing the search space first.
Metadata filters constrain retrieval using structured attributes: document type, timestamp, business unit, source system, or access level. They work especially well when your corpus contains multiple versions, duplicated concepts, or permission-sensitive content.
In enterprise RAG systems, metadata filtering is one of the simplest ways to improve precision and trust.
Reranking improves the candidate set
Reranking reorders retrieved candidates so the strongest evidence appears first before prompt construction. It happens after initial retrieval.
First-pass retrieval optimizes for speed and recall. Precision comes second. A common production pattern: retrieve a broad candidate set with keyword, vector, or hybrid search, then apply a reranking step to surface the most relevant passages.
Reranking adds the most value when top-k retrieval returns loosely related results, context windows are limited, or the best evidence gets buried too low in the prompt.
When these optimizations matter most
You do not need Agentic RAG or GraphRAG to improve retrieval performance. Better query rewriting, decomposition, filtering, and reranking solve a large share of quality issues without adding complexity.
In practice:
- Query rewriting: User inputs are vague or conversational.
- Query decomposition: One request includes multiple retrieval tasks.
- Metadata filters: Structured constraints can narrow the candidate set.
- Rerankers: First-pass retrieval finds relevant material but ranks the best evidence too low.
For many teams, these are the highest-leverage improvements between a working demo and a production-ready RAG system.
RAG Variants for Specialized Workflows
Basic RAG fits many RAG applications, such as question answering tasks and troubleshooting – great for enterprises or SMBs. Some workflows need more structure. Two variants show up often in production discussions: Agentic RAG and GraphRAG.
These variants still use ingestion, chunking, embeddings, and retrieval. They add an extra reasoning layer around retrieval.
Different RAG variants solve different retrieval problems. In practice, the right choice depends less on model preference and more on corpus complexity, answer precision requirements, and operational constraints.
| Variant |
Best use case |
Latency |
Cost |
Complexity |
Best fit |
| Basic RAG |
Simple Q&A over a focused corpus |
Low |
Low |
Low |
Internal docs, FAQs, small knowledge bases, early proofs of concept |
| Hybrid RAG |
Technical, messy, or mixed-format content |
Low to medium |
Low to medium |
Medium |
Enterprise search, policy lookup, support knowledge, content mixing exact terms with semantic meaning |
| Reranked RAG |
Higher-precision answers from noisy top-k results |
Medium |
Medium |
Medium |
Production assistants needing better evidence selection without architectural changes |
| Agentic RAG |
Multi-step workflows requiring planning, tool use, or iterative retrieval |
High |
High |
High |
Research copilots, workflow automation, systems reasoning across multiple actions |
| GraphRAG |
Questions depending on entity relationships, connected knowledge, or multi-hop reasoning |
Medium to high |
Medium to high |
High |
Compliance, investigations, knowledge graphs, enterprise domains with dense relationships |
Agentic RAG
Agentic RAG uses a planner that breaks a request into steps. Each step triggers retrieval or tool calls. Then the system composes the final answer.
This pattern matches multi-part questions. It matches troubleshooting workflows. It matches tasks that span multiple indexes.
The risk surface grows here. Each step adds more chances for prompt injection or data leakage. Security controls must cover the whole trace, not only the final generation.
GraphRAG
GraphRAG adds a graph layer. It extracts entities and relationships from text. It clusters content into communities. It generates summaries for each community. Then it uses those summaries during retrieval and answering.
Microsoft’s GraphRAG site describes this process as extracting a knowledge graph from raw text, building a community hierarchy, generating summaries, and using those structures for RAG tasks.
GraphRAG can help on global questions. These questions span many documents. Plain chunk retrieval can miss the global shape. Community summaries give a top-down path into the corpus.
GraphRAG does add compute and indexing complexity. You run entity extraction, graph build, clustering, and summary generation. So it fits best where global synthesis matters.
Common Technical Challenges of RAG Pipelines and Solutions
Most RAG failures look like model failures. The cause often sits earlier. The fix often sits in data cleanup, chunk design, retrieval scoring, and access control.
|
Challenge
|
Core Issue
|
Key Fix
|
|
Messy data
|
Noisy, outdated, or duplicated content weakens retrieval
|
Audit high-usage sources, dedupe, and add version + freshness metadata
|
|
Fragmentation
|
Truth split across teams and systems leads to partial context
|
Define canonical sources, add tags, and route queries to the right index
|
|
Chunk noise
|
Poor parsing and boundaries drown out signal
|
Strip boilerplate, preserve headings, use semantic chunking, and extract tables cleanly
|
|
Cost & latency
|
Retrieval and long prompts increase cost and response time
|
Use ANN/GPU search, keep fusion simple, and enforce token budgets
|
|
Security & access
|
Private data exposed through generative interfaces
|
Apply access controls at retrieval time and defend against prompt injection
|
Messy data
Messy data creates noisy chunks. Noisy chunks create noisy retrieval. Then the model sees weak evidence and writes a weak answer.
Mess shows up as duplicate versions, broken PDF extraction, repeated boilerplate, and stale docs that still rank high.
Start with a source audit. Pick the top documents that drive usage. Clean that slice first. Then add dedupe rules. Then add version fields and last-updated fields.
Fragmentation
Fragmentation means the truth spreads across many places. Each place uses different terms. Retrieval returns partial evidence. Then the model fills gaps with guesses.
Fragmentation often comes from team structure. One team owns product docs. Another team owns runbooks. A third team owns policy docs. Users still ask one blended question.
A practical fix starts with ownership. Create a canonical set of sources for each domain. Store cross-links. Add tags for product, region, and audience. Then teach routing logic to select the right index for the right query.
Chunk noise
Chunk noise comes from bad parsing and bad boundaries. Headers repeat. Footers repeat. Navigation menus repeat. These tokens drown out the content that matters.
Fix noise at parsing time. Strip repeated page furniture. Preserve heading structure. Use heading-aware splitting. Add semantic chunking for narrative docs where topic breaks matter.
Noise also hides inside tables. Many parsers flatten tables into nonsense text. If users ask table-driven questions, you need stable table extraction. Store table rows with clear separators. Keep column headers with the row text. This preserves structured data for reliable retrieval.
Cost and latency
Latency comes from retrieval, reranking, and generation.
On the retrieval side, ANN indexes cut query time at scale. HNSW supports fast approximate search in high-dimensional spaces.
GPU libraries can also help. The FAISS GPU paper targets billion-scale similarity search with GPUs.
RAPIDS cuVS positions itself as a GPU library for approximate and exact nearest neighbor search and clustering.
Hybrid retrieval can add overhead since it runs multiple retrieval modes. Fusion can stay simple. RRF remains common, and it has a clear formula and clear behavior.
On the generation side, prompt length drives cost. Chunk size, top-k, and summarization steps drive prompt length. Token budgeting needs explicit rules.
Security and access controls
A RAG system connects private content to a generative interface. That shifts security from “model safety” to “data security plus model safety.”
Prompt injection ranks among the core threats. OWASP’s LLM prompt injection cheat sheet describes prompt injection as a vulnerability where malicious input manipulates model behavior, and it notes that instructions and data often mix in one channel.
OWASP’s Top 10 for LLM Applications also treats prompt injection as a key risk category.
In RAG, injection can arrive through user queries and through retrieved documents. A poisoned document chunk can try to override system rules.
Access controls must start before retrieval. Apply authorization checks. Filter by tenant and role. Store ACL fields in metadata. Then enforce those filters in the vector database query.
Prompt construction also matters. Separate instructions from retrieved text with clear delimiters. Label retrieved content as “source text” and treat it as untrusted. Then force the model to follow system rules even if a chunk tries to override them.
RAG Pipeline FAQs for Technical Leaders
How do you know whether your company needs a simple RAG pipeline or a more advanced architecture?
Start simple unless your use case demands strict accuracy, complex document relationships, multi-step workflows, or permission-aware retrieval. A basic pipeline should prove its value early for most internal AI use cases. While advanced patterns like hybrid search, reranking, Agentic RAG, or GraphRAG become more necessary when scale, governance, or answer complexity increases.
What usually goes wrong when companies try to build internal RAG systems on their own?
Teams underestimate how much production quality depends on retrieval, evaluation, and system design. The model itself is rarely the problem. A working demo comes together quickly. Then reality hits, and you’re stuck with noisy source data, poor chunking, weak relevance, inconsistent answers, missing access controls, slow response times, and no clear way to measure improvement.
When does it make sense to outsource RAG development instead of building entirely in-house?
Outsourcing makes sense when your team needs to move fast, avoid costly architectural mistakes, or lacks hands-on experience with production retrieval systems. External support from AI implementation experts adds the most value when the project involves sensitive internal knowledge, multiple data sources, enterprise integration, or a need to reach secure deployment without stalling your core product roadmap.
What should technical leaders evaluate before choosing a RAG development partner?
Look for partners who design for retrieval quality, observability, security, and long-term maintainability. Prototypes are easy. Production systems are hard. The right partner explains trade-offs around ingestion, indexing, retrieval strategy, evaluation, infrastructure, permissions, and deployment architecture in the context of your actual data and business environment.
How do you measure whether a RAG implementation is ready for production?
Production readiness means consistent retrieval of the right context, grounded answers, enforced access controls, and acceptable latency and cost. Test retrieval relevance, answer quality, citation accuracy, failure cases, and operational reliability before expanding usage across teams or workflows.
What kinds of internal use cases benefit most from a custom RAG pipeline?
The strongest fit is internal systems where employees need fast, reliable answers from knowledge sources too large or too dynamic for manual search. Common examples: internal documentation assistants, support enablement tools, policy and compliance search, technical knowledge copilots, and enterprise search that reflects your company’s own data, terminology, and workflows.
Want Help Building a Custom RAG Pipeline? fram^ Can Help
As we’ve discussed, a production RAG pipeline combines ingestion, parsing, indexing, retrieval scoring, prompt templating, evaluation, and security hardening. This guide has given you the blueprint. Your next step is building something your team ships, monitors, and improves.
If you want extra guidance, our AI white paper expands on architecture choices, governance, and rollout patterns you apply across multiple RAG use cases. You can download it here.
It covers infrastructure decisions, deployment patterns, and organizational considerations teams face when scaling RAG systems beyond prototypes.
And if you already have a concrete use case and real users in scope, fram^’s AI implementation services can help you build the pipeline:
- Map your existing systems and data sources to a RAG-friendly architecture
- Design ingestion, chunking, and hybrid retrieval that hit your latency and accuracy targets
- Build evaluation harnesses and observability around the pipeline
- Put security controls in place for access, PII, and prompt injection
Learn more and book an obligation-free call today!